4.3.6. Trees and Random Forests¶
Contents
4.3.6.1. Decision tree¶
The tree growing algorithm can be sketched as follows:
Grow the tree
Given the data, determine the optimal dimension j and splitting point s.
![(j^*, s^*) = \min\limits_{j,s} \left( \min\limits_{c_1} \sum_{i:\, x_i[j] \le s } (y_i - c_1)^2 + \min\limits_{c_2} \sum_{i:\, x_i[j] > s } (y_i - c_2)^2 \right)](_images/math/69d394cec8cdd9b814939afe503f11eb6e8eedb1.png)
where
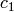 and
and 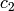 are the labels of the (hypothetical) leaves.
are the labels of the (hypothetical) leaves.- Grow two child trees on the respective data subsets.
- Stop, if the number of data points is below some threshold.
Prune the tree
- Collapse the internal node that produces the smallest per-node increase in the tree cost.
- Stop, if there’s only one node left (the root).
- Out of the produced sequence of trees, select the one that minimizes the total tree cost.
Stumps are single-node trees with the node labels fixed to 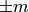 . Also for stumps, the learning consists of finding the
optimal splitting dimension
. Also for stumps, the learning consists of finding the
optimal splitting dimension 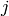 and threshold
and threshold  . Because stumps are classifiers, the 0-1 loss function is used
as error measurement. Thus, each stump has to solve the optimization problem:
. Because stumps are classifiers, the 0-1 loss function is used
as error measurement. Thus, each stump has to solve the optimization problem:
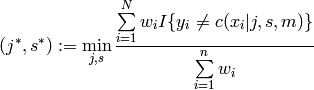
Additionally to the training input, each training sample 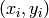 is assigned a weight
is assigned a weight 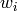 that represents how
much a misclassification of the sample contributes to the classifier cost.
that represents how
much a misclassification of the sample contributes to the classifier cost.
4.3.6.3. Interfaces¶
- class ailib.fitting.Tree(leafThres=5)¶
Bases: ailib.fitting.model.Model
Decision tree skeleton.
Warning
Don’t use this class directly. Use RegressionTree or ClassificationTree instead.
Parameter: leafThres (int) – Minimum number of data points per node. - cleanData()¶
Remove the data from the tree.
Only the data member is cleared. The node label is recomputed first.
- collude()¶
Collapses the childs of the node.
The childs’ data is collected in this node and the label recomputed. The childs will be deleted. The node will become a leaf.
- costSplit(j, s)¶
- costTerminal(data)¶
- costTree(alpha)¶
- data()¶
- Return the data of all child nodes.
- depth()¶
- Return the maximal depth of the tree.
- eval(x)¶
- Find the label of a data point x.
- grow(data)¶
Grow a tree on training data.
Finds the optimal splitting parameters of the data and grows two child trees (if there are enough data points left).
Parameter: data (STD) – Training data.
- isLeaf()¶
- Return true, if the node has no childs (is a leaf node).
- leaves()¶
- Return the number of leaves.
- prune(alpha)¶
Prune the tree to find the tree with minimal cost.
The tree is pruned according to weakest link pruning until there’s only one node left. Then, the tree with minimal total cost is restored.
Parameter: alpha (float) – Pruning parameter. Controls, how much the tree size influences its cost.
- class ailib.fitting.Stump(labelValue=1.0)¶
Bases: ailib.fitting.model.Model
Parameter: labelValue (float) – Label of the class. - err((x, y))¶
- 0-1 loss function.
- eval(x)¶
- Compute the label of a data point x.
- fit(data, weights=None)¶
Train the stump on the presented data.
Finds the optimal dimension and splitting point to split the data in two subsets. The optimal parameters are found w.r.t. to the data weights. If no weights are given, a uniform distribution is assumed.
Parameters: - data (STD) – Data points.
- weights ([float]) – Weights of data points. Needs not to be normalized.